
Создание баз данных в
InterBase SQL Server
|
Создание баз данных вInterBase SQL Server |
|
|||
| Банников Н.А. | www.stikriz.narod.ru | Почта | На главную страницу | ||
| Создание
базы данных Создание таблиц Связывание таблиц Суррогатные ключи "Деревянные" списки Работа с событиями Работа с исключениями Процедуры, триггеры UDF функции |
|
Я не буду загромождать текст подробным описанием всех операторов для создания объектов в базе данных. Для этого есть документация. Наоборот, на простых примерах постараюсь показать как и когда нужно делать так или иначе. Здесь описывается работа с SQL сервером InterBase 6.0. Если Вы новичок, то прочитайте документ о концепциях построения баз данных >>>.
База данных создается простым скриптом. Здесь и в дальнейшем я буду SQL операторы выделять жирным шрифтом.
CREATE DATABASE '...\PFO_POKAZATELI.GDB'
USER 'ADM_PFO_POK' PASSWORD '12345'
PAGE_SIZE = 8192
DEFAULT CHARACTER SET WIN1251;
CREATE DATABASE -
это и есть оператор, который создаст базу
данных. База данных будет представлять из
себя файл, который будет создан в каталоге,
указанном после оператора. Расширение
файла может быть любым, но принято, что GDB -
расширение для файла базы данных, а,
например, GBP - для резервной копии.
USER и PASSWORD задают имя
пользователя и пароль. Этот пользователь
должен быть зарегистрирован на сервере до
создания базы данных, иначе InterBase выдаст
сообщение об ошибке.
PAGE SIZE задает размер странички
данных в файле по умолчанию. Страничка
будет скачиваться с жесткого диска только
целиком. Поэтому, можно считать, что это
минимальный размер буфера работы с файлом
базы данных. Страничка должна быть такого
размера, чтобы в неё поместилась хотя бы
одна запись в любой из таблиц. Здесь не
нужно учитывать размер BLOB поля, т.к. для его
хранения выделяются дополнительные
страницы. Размеры страниц могут быть от 1024
до 8192 Kb. Размер страниц влияет на
быстродействие и степень заполнения
данными файла базы данных. Так, если
следующая запись не помещается полностью в
активную страницу, то для неё будет
выделена новая страница. Поэтому следует
стремиться к кратному странице размеру
записи. Это, конечно весьма проблематично, т.к.
у Вас в БД может быть несколько таблиц с
разными размерами записи. Слишком большой
размер страницы приводит к считыванию с
диска записей, которые могут не
понадобиться в выходных данных запроса, что
должно снижать быстродействие всей системы
в целом. Очевидно, это происходит при
маленьких размерах записи по сравнению с
размером страницы. Однако, многочисленные
опыты показывают, что быстродействие может
и снижается, но на такую маленькую величину,
которую невозможно зафиксировать и
измерить в реальных грамотно построенных
приложениях.
DEFAULT CHARACTER SET определяет кодировку
символов в базе данных. Если Вы
намереваетесь использовать русский язык,
то Вам следует установить значение WIN 1251.
Для других языков есть свои кодировочные
таблицы.
Обычно базу данных создают в
IBConsole. Там нужно выбрать пункт меню "Database|Create
Database". В появившемся окне заполнить
поля ввода параметров операторов для
создания БД.
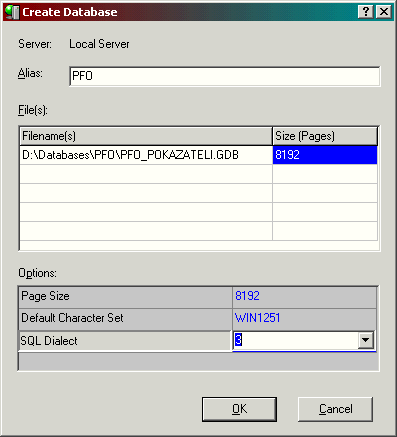
Вы можете создать БД из нескольких файлов, которые будут заполняться данными по очереди. Или создать зеркало на другом жестком диске для защиты от крушения основного жесткого диска (см. документацию).
InterBase - это не совсем
то, о чем писал Кодд. Здесь полностью не
реализовано понятие домена. Домены служат в
InterBase не для связи таблиц по первичному и
внешнему ключу, а для описания типа поля,
определенного пользователем. Более того,
если Вы начнете создавать таблицы с полями
стандартного типа, то каждому из этих полей
будет поставлен в соответствие свой домен.
Это приводит к тому, что количество
объектов в базе данных прирастает за счет
доменов прямо пропорционально количеству
полей всех таблиц. Поэтому, обычно создают
достаточное количество доменов для
описания таблиц в БД, а потом создают сами
таблицы. Вот выдержка из реальной базы
данных для создания доменов:
CREATE DOMAIN IZMER_NUM INTEGER NOT NULL;
CREATE DOMAIN ACTIVITIES_NUM INTEGER NOT NULL;
. . .
CREATE DOMAIN NAMES_TYPE VARCHAR(45) COLLATE
PXW_CYRL;
CREATE DOMAIN FLOAT_TYPE DOUBLE PRECISION;
CREATE DOMAIN BOOL_TYPE CHAR(1) DEFAULT "F" CHECK(VALUE
= "T" OR VALUE = "F");
CREATE DOMAIN FORMULA_TYPE BLOB SUB_TYPE 1 SEGMENT SIZE
256 CHARACTER SET WIN1251;
CREATE DOMAIN INTEGER_TYPE INTEGER;
. . .
CREATE DOMAIN BY_USER VARCHAR(30) DEFAULT
USER;
CREATE DOMAIN BY_DATE TIMESTAMP DEFAULT "now";
Команда CREATE DOMAIN создает новый домен.
Далее, идет имя домена. Затем - его тип. Есть
множество типов данных, которые
поддерживает InterBase. Вы можете узнать эту
информацию из документации. Далее, можно
задать ограничения на значение, заводимое в
поле таблицы типа этого домена. Например, NOT
NULL обязывает всегда заводить какие-нибудь
данные в это поле при добавлении новой
строки в таблицу, т.е. это поле обязательно
должно быть заполнено. DEFAULT "F"
заполняет поле значением по умолчанию -
символом "F". Конструкция CHECK(VALUE
= "T" OR VALUE = "F") проверяет выход
значения поля за заданные границы.
Конструкция COLLATE PXW_CYRL позволяет
правильно вести сортировку строк таблицы
по полю типа этого домена. Эта конструкция
применяется при создании домена или при
объявлении индекса (об этом позже).
Конструкция CREATE DOMAIN FORMULA_TYPE BLOB SUB_TYPE
1 SEGMENT SIZE 256 CHARACTER SET WIN1251 создает домен
типа BLOB, т.е. набор байтов, которые
рассматриваются как текст (SUB_TYPE 1),
странички в файле БД для этого текста
выделяются по 256 байт сразу и текст в этом
поле записывается в кодировке WIN1251.
Последние два домена могут хранить
информацию о пользователе и дату и время о
последнем изменении записи.
Теперь создадим какую-нибудь
таблицу.
CREATE TABLE IZMER_NAMES
(
ID_NUM IZMER_NUM,
NAME NAMES_TYPE,
USER_NAME BY_USER,
CHANGE_DATE BY_DATE,
PRIMARY KEY(ID_NUM)
);
Оператор CREATE TABLE собственно,
создает таблицу, далее идет её уникальное в
пределах БД имя. Между скобками стоят
определения столбиков таблицы и
дополнительные операторы. Мы видим, что
таблица состоит из четырех столбиков, а их
тип описан через домены, которые мы описали
ранее. Если Вы создадите еще одну таблицу с
полем типа NAMES_TYPE, то количество доменов у
Вас не увеличится, а если бы Вы создали две
таблицы, у которых было бы по одному полю
типа VARCHAR(45), то это привело бы к созданию
двух доменов, описывающих эти поля. Причем,
имена этих доменов присвоились бы по
умолчанию, а значит, совершенно
нечитабельные. Оператор PRIMARY KEY пределяет
имя или имена полей, которые
рассматриваются как первичный ключ. Поля
первичного ключа должны быть NOT NULL и
сочетание их значений должно быть
уникально в пределах таблицы. Это как бы
отпечаток пальцев записи - набор значений
полей, по которым мы всегда сможем отличить
одну запись от другой. Если Вы не можете
выделить первичный ключ в таблице для
хранения Ваших данных, значит, скорее всего,
Вы недостаточно хорошо продумали все
вопросы по хранению данных в таблице.
Связать можно хотя бы две
таблицы, поэтому определим вторую:
CREATE TABLE ACTIVITIES
(
ID_NUM ACTIVITIES_NUM,
ID_IZMER_NAMES IZMER_NUM,
POZITION INTEGER_TYPE,
NAME NAMES_TYPE,
IS_DECCIPHERAD_INFO BOOL_TYPE,
USER_NAME BY_USER,
CHANGE_DATE BY_DATE,
PRIMARY KEY(ID_NUM),
FOREIGN KEY(ID_IZMER_NAMES) REFERENCES IZMER_NAMES(ID_NUM)
);
Во второй таблице есть поле с
типом IZMER_NUM - это домен, который
используется в первой таблице для
определения поля первичного ключа. Мы можем
создать внешний ключ для связи двух таблиц: FOREIGN
KEY(ID_IZMER_NAMES) REFERENCES IZMER_NAMES(ID_NUM). Что
буквально означает: "Внешний ключ по полю
ID_IZMER_NAMES как ссылка в таблицу IZMER_NAMES по полю
ID_NUM". Такая связь гарантирует нам, что в
таблице IZMER_NAMES всегда будет присутствовать
строка с номером, который мы запишем в поле
ID_IZMER_NAMES. Если кто-нибудь попытается удалить
из справочника единиц измерения строку,
которую мы используем в справочнике
деятельности, то произойдет исключительная
ситуация. Такое поведение БД называется
контроль ссылочной целостности.
Теперь, немного слов о плане
построения БД. Хорошо, если у Вас есть какой
никакой Case инструмент, например, Rational Rose.
Говорят, что в Microsoft Office появился Visio. Я
подозреваю, что это что-то не совсем то, что
нужно, но лучше сейчас работать хоть на чем-то,
чем долго ждать хороший инструмент. Ну, а
если нет Case, то следует учитывать ряд
небольших правил:
Есть два типа ключевых полей. Первое - это естественные ключи. Возьмем, к примеру, медицинскую карту в поликлинике. Естественный ключ - это номер медицинской карты. На медицинскую карту "цепляются" талоны (связь главный - подчиненные), у которых естественный ключ - это номер медицинской карты больного, отчетный год и номер талона (с нового года нумерация начинается с единицы). К талонам "цепляются" посещения, у которых естественный ключ - номер медицинской карты больного, отчетный год, номер талона и дата посещения. К посещениям - услуги и т.д. Мы видим, что размер первичного ключа увеличивается, по крайней мере, на одно поле с каждой новой таблицей. Соответственно, растет вычислительная нагрузка, которую можно оценить мощностью домена, на сервер БД. Как же можно противостоять разрастанию первичного ключа? Многие программисты, и я в том числе, считают, что уникальность записи и первичный ключ - это понятия, вообще-то разные, поэтому мы всегда, где это нужно, применяем т.н. сокращение первичного ключа. Для этого используются суррогатные (т.е. неестественные) ключи. Что такое суррогатный ключ? Это поле целого типа, которое имеет уникальное значение, образующее домен с другими таблицами. Возьмем, для примера, случай с поликлиникой. Для таблицы с талонами вводится уникальное поле целого типа, в котором будет хранится последовательность целых чисел 1, 2, 3 ... N и т.д. Это поле объявлено первичным ключом, а чтобы не завести несколько талонов с одинаковыми номерами, объявляется уникальный индекс по полям отчетный год и номер талона. Внешний ключ, как и положено - по полю номера медицинской карты. В результате, мы сократили размер первичного ключа, который теперь является суррогатным. Эти целые числа будут использоваться в таблице с посещениями, где тоже можно сокращать первичный ключ. Заметьте, что в таблице с посещениями, теперь, не нужно хранить не номер медицинской карты, не отчетный год, не номер талона, а только значение первичного ключа, т.е. одно целое число на запись.
Вот несколько примеров для
работы с суррогатными ключами.
Для начала, нужно создать механизм
поддержки уникальности значений
суррогатного ключа.
CREATE GENERATOR GET_IZMER_NAMES_NUM;
Этот оператор создает т.н. генератор, где
будет хранится предыдущее значение нашей
уникальной последовательности целых чисел.
Механизм гарантирует, что только один
пользователь может иметь доступ к
генератору в один момент времени. Остальные
будут ждать, пока генератор не освободится.
SET GENERATOR GET_IZMER_NAMES_NUM TO 50;
Этим оператором мы установили начальное
значение генератора. Далее, можно либо
создать триггер, который сработает при
добавлении новой записи в таблицу, либо
создать простенькую процедуру, которая
вернет очередное значение из генератора:
SET TERM !! ;
CREATE PROCEDURE SET_IZMER_NAMES_NUM
RETURNS(NUM INTEGER)
AS
BEGIN
NUM = GEN_ID(GET_IZMER_NAMES_NUM, 1);
END!!
SET TERM ; !!
GEN_ID - это встроенная процедура, которая
просто увеличивает значение генератора на
величину, переданную во втором параметре и
возвращает результат. Если Вы используете
триггер, то после добавления новой записи,
Вам придется обновлять весь набор данных,
чтобы знать значение первичного ключа,
поэтому лучше использовать процедуру.
Бывают случаи, когда
отношение главный-подчиненный присуще
записям одной и той же таблице, например,
отношения между отделами организации или
между структурами госаппарата и т.д. и т.п.
Одна запись может быть главной для
нескольких других, которые в свою очередь
могут быть главными для следующих. Такая
структура напоминает дерево с ветвями,
расположенными вниз по таблице. Первая
запись (записи) - главный узел (узлы) от
которых идут ветви (подчиненные записи).
Если эти записи имеют свои подчиненные (вложенные)
записи, то они образуют следующие по
иерархическому списку узлы. Проще всего,
представить это в пространстве в виде слоев
записей. Каждая запись может содержать в
себе вложенный слой с записями. Несмотря на
всю кажущуюся сложность, реализация такой
структуры очень проста. Для этого нужно
иметь, как минимум, два столбика в таблице:
первый столбик - это суррогатный первичный
ключ, а второй - ссылка на первый столбик со
значением первичного ключа записи -
владельца. Вот реализация такой таблицы:
CREATE TABLE ACTIVITIES
(
ID_NUM ACTIVITIES_NUM,
ID_OWNER ACTIVITIES_NUM,
ID_IZMER_NAMES IZMER_NUM,
POZITION INTEGER_TYPE,
NAME NAMES_TYPE,
USER_NAME BY_USER,
CHANGE_DATE BY_DATE,
PRIMARY KEY(ID_NUM),
FOREIGN KEY(ID_IZMER_NAMES) REFERENCES IZMER_NAMES(ID_NUM)
);
Таблица содержит первичный ключ
в поле ID_NUM, ссылку на главную запись в поле
ID_OWNER, ссылку на единицу измерения в поле
ID_IZMER, поле POZITION целого типа, определяющее
позицию записи, для возможности
перемещения записи вверх и низ,
наименование вида дечтельности в поле NAME.
Далее, идут счетчик и процедура для работы с
первичным ключом.
CREATE GENERATOR GET_ACTIVITIES_NUM;
SET GENERATOR GET_ACTIVITIES_NUM TO 50;
SET TERM !! ;
CREATE PROCEDURE SET_ACTIVITIES_NUM
RETURNS(NUM INTEGER)
AS
BEGIN
NUM = GEN_ID(GET_ACTIVITIES_NUM, 1);
END!!
SET TERM ; !!
Далее, идет индекс для сортировки
строк по позиции. Имя POZITION принято мной не
потому, что я не знаю о английском слове
POSITION, а потому, что POSITION - зарезервированный
идентификатор SQL.
CREATE UNIQUE INDEX ACTIVITIES_POSITION ON ACTIVITIES(ID_OWNER,
POZITION);
Триггер UPDATE_ACTIVITIES обновляет
значения полей, идентифицирующиз
пользователя внесшего последние изменения.
SET TERM !! ;
CREATE TRIGGER UPDATE_ACTIVITIES FOR ACTIVITIES
BEFORE UPDATE AS
BEGIN
NEW.USER_NAME = USER;
NEW.CHANGE_DATE = 'now'
END!!
SET TERM ; !!
Наконец, добавлен внешний индекс
таблицы на саму себя. В описании таблице это
нельзя было сделать,т.к. ни поля ID_OWNER, ни
поля ID_NUM, ни самой таблицы не существовало.
ALTER TABLE ACTIVITIES
ADD
FOREIGN KEY (ID_OWNER) REFERENCES ACTIVITIES(ID_NUM) ON DELETE
CASCADE;
Далее, идет процедура
перемещения строки в слое данных вверх или
низ. Подразумевается, что в слое не более
2147483646 строк.
SET TERM !! ;
CREATE PROCEDURE SET_ACTIVITIES_POSITION(OWNER_NUM INTEGER, OLD_POSITION
INTEGER, NEW_POSITION INTEGER)
AS
BEGIN
UPDATE ACTIVITIES
SET
POZITION = 2147483647
WHERE
POZITION = :NEW_POSITION AND
ID_OWNER = :OWNER_NUM;
UPDATE ACTIVITIES
SET
POZITION = :NEW_POSITION
WHERE
POZITION = :OLD_POSITION AND
ID_OWNER = :OWNER_NUM;
UPDATE ACTIVITIES
SET
POZITION = :OLD_POSITION
WHERE
POZITION = 2147483647 AND
ID_OWNER = :OWNER_NUM;
END!!
SET TERM ; !!
Тут не хватает только триггера
для начального определения значения поля
POZITION. Я думаю, что Вы сможете самостоятельно
создать триггер в качестве пробы сил.
Это совсем просто:
SET TERM !! ;
CREATE TRIGGER CHANGE_ACTIVITIES FOR ACTIVITIES
AFTER UPDATE POSITION 0 AS
BEGIN
POST_EVENT 'Update Activities !';
END!!
SET TERM ; !!
Осталось только
зарегистрировать это событие в приложении
пользователя, и если оно произойдет на
сервере, то приложение пользователя его
получит. Так можно, например, наблюдать за
изменениями курсов валют на бирже. При
изменении курса, клиент получает событие и
пере открывает запрос, чтобы увидеть
изменения.
Для начала, исключение
нужно определить в БД.
CREATE EXCEPTION DELETE_MAIN_PARENT
' DO NOT DELETE THIS RECORD ! THIS RECOCT IS PARENT FOR ALL RECORDS. ';
Далее, нужно определить триггер,
который поймает исключительную ситуацию.
Например, при удалении главного узда дерева,
удалится вся БД целиком. Понятно, что такого
быть не должно. Давайте поймаем это
исключение.
SET TERM !! ;
CREATE TRIGGER CHECK_DELETE_TYPES FOR ACTIVITIES
BEFORE DELETE POSITION 0 AS
BEGIN
IF (ACTIVITIES.ID_NUM = ACTIVITIES.ID_OWNER) THEN
EXCEPTION DELETE_MAIN_PARENT;
END!!
SET TERM ; !!
Если исключительная ситуация
наступит, то пользователю ничего не
останется сделать, кроме как отменить
транзакцию.
Понятия процедур и
триггеров должно, прежде всего,
ассоциироваться с понятием бизнес-логика.
Процедуры реализуют документированный
интерфейс к данным в БД, а триггеры -
проверку корректности вводимых данных и
закулисную работу. Если у Вас есть
возможность переложить всю бизнес-логику
на сервер в виде триггеров и процедур, то
так и нужно поступать. Даже если Вы в
программе контролируете правильность
вводимых данных, не забудьте в БД
продублировать это же в триггере. Такой
подход гарантирует, что при написании
дополнительного модуля или еще одной
программы, оперирующей с данными БД, Вам не
удастся нарушить правила работы с данными.
Я думаю, что примеров триггеров и процедур
было достаточно. Но, начинающие
программисты часто отказываются от
использования этого мощнейшего механизма
БД из за досадных ошибок в синтаксисе
запросов. Им кажется, что в приложении
пользователя легче сделать то же самое, к
тому же и работает оно быстрее... Это
заблуждение. Одно дело, когда Вы пишете и
тестируете программу локально, и совсем
другое, когда к БД подключены пользователи.
Никакая программа не сделает изменения в БД
так же быстро и корректно, как встроенные
механизмы. Вот тогда они будут работать
локально, а ваша программа - по сети. Поэтому
я дам без комментариев пример процедуры с
большим количеством операторов. Из этого
примера будет ясно где ставить, а где нет
точки с запятыми, двоеточия и т.д. Думаю,
что это поможет Вам в Ваших разработках.
SET TERM !! ;
CREATE PROCEDURE CHECK_USER_SECURITY(ID_USER INTEGER, ID_DOC INTEGER,
UP_TREE INTEGER)
RETURNS(IS_SHOW CHAR(1), IS_EDIT CHAR(1), IS_APPEND CHAR(1), IS_DELETE CHAR(1))
AS
DECLARE VARIABLE TREE_NUMBER INTEGER;
DECLARE VARIABLE TREE_OWNER INTEGER;
DECLARE VARIABLE USER_NUM INTEGER;
DECLARE VARIABLE DOC_NUM INTEGER;
DECLARE VARIABLE EDITING CHAR(1);
DECLARE VARIABLE APPENDING CHAR(1);
DECLARE VARIABLE DELETING CHAR(1);
BEGIN
IS_EDIT = 'F';
IS_APPEND = 'F';
IS_DELETE = 'F';
IS_SHOW = 'F';
FOR SELECT ID_NUM, ID_OWNER
FROM DATA_LIST
WHERE DATA_LIST.ID_NUM = :ID_DOC
INTO TREE_NUMBER, TREE_OWNER
DO
BEGIN
IF ( TREE_NUMBER = UP_TREE ) THEN EXIT;
FOR SELECT ID_USER, ID_DOC, IS_EDIT, IS_APPEND, IS_DELETE
FROM DOCS_USERS
WHERE DOCS_USERS.ID_USER = :ID_USER
INTO USER_NUM, DOC_NUM, EDITING, APPENDING, DELETING
DO
BEGIN
IF ( TREE_NUMBER = DOC_NUM ) THEN
BEGIN
IS_EDIT = EDITING;
IS_APPEND = APPENDING;
IS_DELETE = DELETING;
IS_SHOW = 'T';
EXIT;
END
END
ID_DOC = TREE_OWNER;
END
END!!
SET TERM ; !!
Эта процедура используется
сервером приложений для проверки прав
пользователя в таблице в виде
иерархического дерева. Понятно, что
определить права пользователя к отдельной
записи стандартными путями нельзя, поэтому
вся БД работает под управлением сервера
приложений и посредством DCOM дает
интерфейсы клиентам. Т.к. сервер приложений
запущен в адресном пространстве сервера, то
такой подход к Security можно считать
оправданным.
Обычно, тут дают пример, как
посчитать какую-нибудь математическую
формулу, и вернуть её результат как столбик
ответа на запрос. Я же решил показать пример
со строками, т.к. это первое, на чем обычно
впервые спотыкаются. Это только пример. В
реальной БД такого не делают. Итак, добавим
в таблицу ACTIVITIES поле TREE_INFO VARCHAR(255). Будем в
нем хранить путь от главного узла. Этот путь
проще всего строить в триггере по
добавлению записи в таблицу. Но сама строка
с путем будет создаваться в DLL. Для начала
объявим нащу функцию в DLL:
DECLARE EXTERNAL FUNCTION CREATEPATH(CSTRING(256), INTEGER)
RETURNS CSTRING(256)
ENTRY_POINT "CreatePath"
MODULE_NAME "UDF_INCL";
Мы указали имя в БД, передаваемые
переметры, возвращаемое значение, имя в DLL, и
имя самой DLL. Эта библиотека должна
находится в каталоге UDF. У меня это D:\Program
Files\Borland\InterBase\UDF. А использовать функцию
будем так:
SET TERM !! ;
CREATE TRIGGER INSERT_ACTIVITIES FOR ACTIVITIES
BEFORE INSERT
AS
DECLARE VARIABLE PATH_TREE VARCHAR(256);
BEGIN
SELECT TREE_INFO
FROM ACTIVITIES
WHERE (NEW.ID_OWNER = ID_NUM)
INTO PATH_TREE;
NEW.TREE_INFO = CREATEPATH(PATH_TREE, NEW.ID_NUM);
END!!
SET TERM ; !!
В InterBase все UDF передают в
параметрах ссылки, поэтому строку передают
как указатель. Используются VARCHAR строки, т.к.
они явно не дополняются пробелами до
максимальной длины. Иначе, Вы бы уже ничего
к ней не прибавили. Вот реализация DLL в Delphi:
library UDF_INCL;
//
//
// Copyright 2000 Bannikov N.A. Stikriz Technology
//
//
uses
SysUtils,
Classes;
{$R *.RES}
function CreatePath(MainPath: PChar; var IntVal: LongInt): PChar; cdecl;
export;
begin
Result:=PChar(AnsiString(MainPath)+IntToStr(IntVal)+'\');
end;
exports
CreatePath;
begin
end.
Банников Н.А. www.stikriz.narod.ru почта 2000 г.